
The cloud giant Amazon Web Services (AWS) is a hub for many dynamic and game-changing solutions for organizations and enterprises. Since its inception, it has offered staggering offerings that have revolutionized the digital landscape. AWS Data Pipeline is one of its many solutions that helps businesses automate data transformation and movement.
Using AWS Data Pipeline, businesses can swiftly begin with Amazon Web Services and establish data-driven workflows and parameters for data transformations. They also utilize the pipeline to transfer data to different Amazon Web Services for analysis, including Amazon DynamoDB, Amazon RDS, and more.
This AWS blog post will discuss and explore the meaning, core components, benefits, and listed pros and cons of the AWS Data Pipeline for your consideration.
Table of Contents
What is AWS Data Pipeline?
Amazon Web Services provides a robust data pipeline for efficiently processing and transferring data between various AWS computing and on-premises sources and storage services at specified intervals. Amazon EMR empowers developers to streamline the execution of big data frameworks on AWS for processing and analyzing massive volumes of data.
The AWS data pipeline is essential for businesses to consolidate and transfer their data effectively, supporting various data-driven initiatives. It comprises three critical elements: a source, processing step(s), and destination, which are vital for optimizing data movement across digital platforms. This pipeline enables data transfer from a data lake to an analytics database or a data warehouse.
AWS Data Pipeline Key Components
Source: The location from which a pipeline retrieves information (RDBMS, CRMs, ERPs, social media management tools, or IoT sensors).
Destination: The extracted information is stored in a data lake or warehouse and can be used in data visualization tools for analysis.
Data Flow: Data changes as it moves from the source to the destination, known as data flow. ETL stands for extract, transform, and load, a common data flow approach.
Processing: Data processing involves extracting, transforming, and moving data to a destination, as well as determining the data flow implementation, such as batch or stream processing for ingesting data.
Workflow: Workflow involves sequencing jobs based on their dependencies in a pipeline to ensure that upstream jobs are completed before downstream jobs can begin.
Monitoring: Consistent monitoring is crucial for ensuring data accuracy, speed, and efficiency, especially as data size increases.
Need for an AWS Data Pipeline: Benefits!
For Data Consolidation – The cloud’s expansion means that modern businesses use multiple apps for various functions, leading to data silos and fragmentation. This makes it difficult to obtain simple business insights. Consolidating data into a single destination using a pipeline can help address this issue.
For Quicker Information/Insights Access – Analyzing and transforming data into insights is crucial for businesses. An automated process is needed to extract data from databases and transfer it to analytics software.
For example, companies can use an AWS data pipeline to consolidate sales data from different platforms and gain insights into customer behavior.
For Firm Decision Making – In today’s fast-paced business environment, even a short delay can result in lost opportunities. For example, sales and customer service teams need real-time data to offer the right products and provide satisfactory service. AWS pipelines help companies extract and process data for up-to-date insights and informed decision-making.
To Meet Peeks in Demand — Multiple organizations need quick access to data, so the business must rapidly add storage and processing capacity. Traditional pipelines are inflexible, slow, and difficult to scale, while the AWS Data Pipeline is scalable and simplifies processing large numbers of files.
Pros
Reliable — The AWS Cloud Pipeline is built on a highly available, fault-tolerant infrastructure. Users can rent virtual computers with Amazon EC2 to run applications and pipelines, and the AWS Pipeline can automatically retry activities in case of failure.
Easy to Use — AWS offers a drag-and-drop option for users to design pipelines without writing code. Users only need to provide the name and path of the Amazon S3 bucket. AWS also provides template libraries for quick pipeline design.
Scalable – The AWS pipeline’s flexibility makes it highly scalable, enabling the processing of a million files as quickly as a single file, in serial or parallel.
Low Cost – AWS Pipeline pricing is cost-effective, billed at a low monthly rate, and includes free trials and $100,000 in AWS credits for new customers.
- Three low-frequency preconditions running on AWS.
- Five low-frequency activities running on AWS
Flexible – The AWS pipeline can run SQL queries directly on databases or configure and run tasks like Amazon EMR. It can also execute custom applications at organizations’ data centers or on Amazon EC2 instances for data analysis and processing.
Cons
- It’s tailored for AWS services and works well with all AWS components. However, better choices may exist if you need data from external services.
- Managing multiple installations and configurations on computing resources while working with data pipelines can be overwhelming.
- To beginners, representing preconditions and branching logic in the data pipeline may seem complex. However, tools like Airflow make handling complex chains easier.
Get Started With AWS Data Pipeline
AWS allows you to create data pipelines in a variety of ways, including:
- By using AWS Data Pipeline Templates
- By using the Console Manually
- By using the AWS Command Line Interface in JSON format
- By using an AWS SDK with a language-specific API
But, if you wish to create an AWS data pipeline manually using console templates, follow the below steps:
- Open the “Data Pipeline Console”
2. Next, you might encounter one of two screens:

- The Console displays an introductory screen that says, “If you still need to create a pipeline,”
- The Console will display your previous regional pipelines if you’ve already created one.
3. Under the Name section, enter your pipeline name.
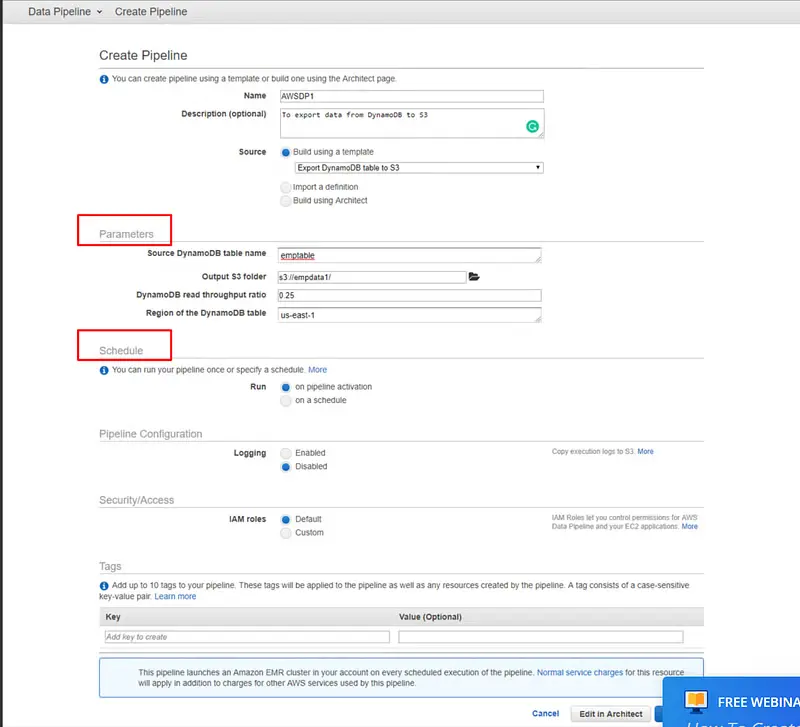
4. include a description in your pipeline’s “Description” section.
5. Next, choose “Build using a template,” then select any template, such as “Import DynamoDB backup data from S3.”
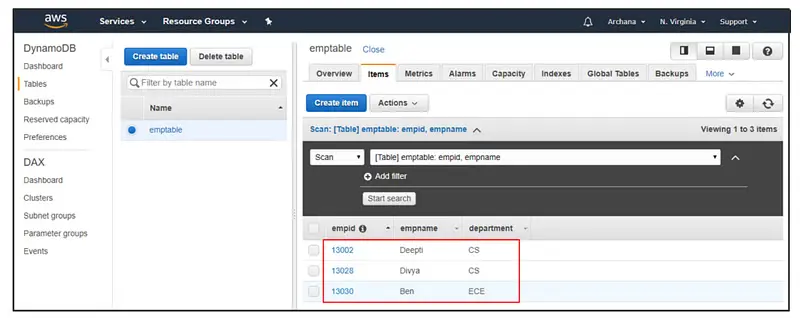
6. If you use a resource managed by AWS Data Pipeline, you can add a bootstrapAction to the Amazon EMR Cluster object. However, AWS Data Pipeline supports only the Amazon EMR cluster version 6.1.0.
7. Set the Input S3 folder to s3://elasticmapreduce/samples/Store/ProductCatalog under the parameter and the DynamoDB table name to your table’s name.
8. Under “Schedule,” select “pipeline activation.”
9. Under Pipeline Configuration, keep logging enabled. Then, click the folder icon below the S3 location for logs, choose a folder, and click Select.
10. Under “Security/Access,” please leave the IAM roles set to default.
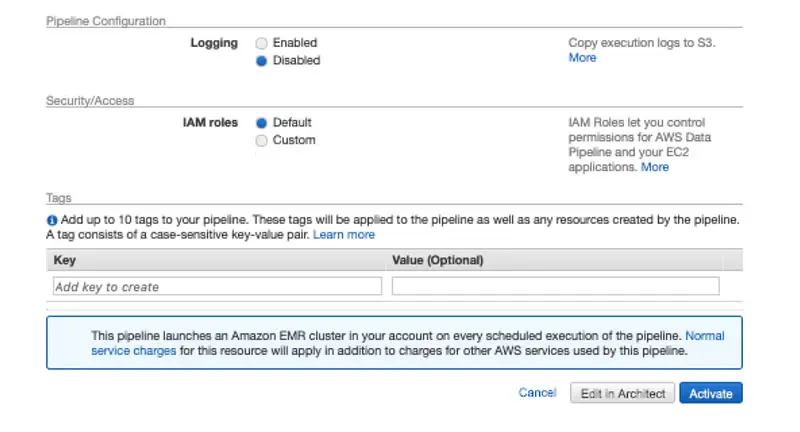
11. Final step: “Click Edit in Architect.”
We have created the above pipeline using the DynamoDB template. To manage Amazon services, you can use alternative tools like AWS CLI. In contrast, you can hire dedicated AWS developers from a renowned AWS Development Company to get started with the AWS Data Pipeline.
Final Thoughts
Today’s businesses generate massive amounts of data through their websites, Apps, social media (SM) platforms, and other channels. Amazon Web Services’ data pipeline provides an excellent solution for effectively managing, processing, and storing this data.
It’s one of the most trusted and adopted solutions, proven more reliable and secure. Many have already implemented this, and now it’s your turn to get the most out of AWS’s staggering offerings. Contact us today to explore AWS Data Pipeline and its impact on your business.




